Abstract
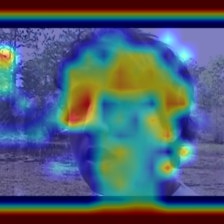
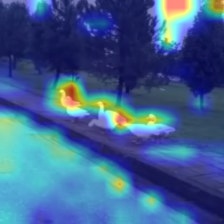
Speech enhancement plays an essential role in various applications, and the integration of visual information has been demonstrated to bring substantial advantages. However, existing works mainly focus on the analysis of facial and lip movements, whereas contextual visual cues from the surrounding environment have been overlooked: for example, when we see a dog bark, our brain has the innate ability to discern and filter out the barking noise. To this end, in this paper, we introduce a novel task, i.e. Scene-aware Audio-Visual Speech Enhancement. To our best knowledge, this is the first proposal to use rich contextual information from synchronized video as auxiliary cues to indicate the type of noise, which eventually improves the speech enhancement performance. Specifically, we propose the VC-S\(^{2}\)E method, which incorporates the Conformer and Mamba modules for their complementary strengths. Extensive experiments are conducted on public MUSIC, AVSpeech and AudioSet datasets, where the results demonstrate the superiority of VC-S\(^{2}\)E over other competitive methods. We will make the source code publicly available. Project demo page: https://AVSEPage.github.io
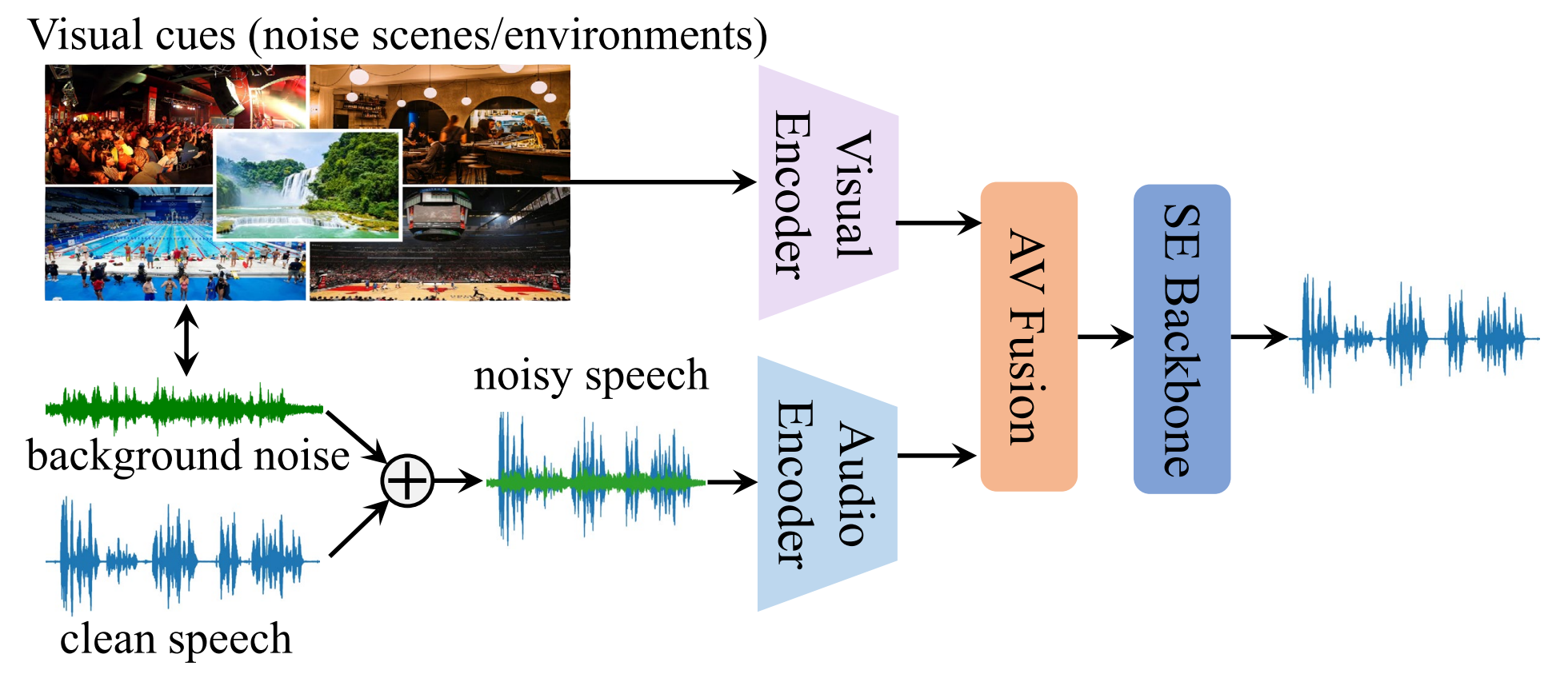
Our task